How Google tricks itself to protect Chrome user privacy
An open-source project called Rappor uses randomly muddled data to let Google gather information about people's software usage while keeping individuals' behavior private.


- Shankland covered the tech industry for more than 25 years and was a science writer for five years before that. He has deep expertise in microprocessors, digital photography, computer hardware and software, internet standards, web technology, and more.

It's a sticky issue for software developers: how do you gather data about your product's users without invading their privacy?
One solution, as embodied in a new Google open-source project called Rappor, is to have the software send data that you know is wrong.
That approach may seem counterintuitive, given how much effort data gatherers usually devote to screening out bad data. The key to Google's approach, though, is a trick called randomized response that still lets the truth shine through, according a blog post Thursday by Úlfar Erlingsson, a manager in Google's security research division.
Rappor allows "the forest of client data to be studied, without permitting the possibility of looking at individual trees," according to a draft paper on Rappor.
Google is testing the approach in its Chrome browser. It's been gathering data on what sites people set as their browser's default homepage so Google can get a better handle on malware that tries to change people's homepages. About 14 million users are participating in that study, drawn from the larger population of people who've agreed to let Chrome send usage data back to Google.
Related Links
- Android 6.0 Marshmallow is official and coming later this year
- Google wants to become the one-stop shop of tech
- Google's $379 Nexus 5X is your cheapest ticket to pure Android Marshmallow bliss
- All-metal Nexus 6P flagship phone showcases Android 6.0 Marshmallow on huge 5.7-inch screen
- Google announces Pixel C tablet; starts at $499 for 32GB version, $599 for 64GB model
- Google releases improved Chromecast for the same $35 price
- Chromecast Audio is a dedicated phone-controlled music streamer that costs just $35
It's an interesting project for a company with as much personal data as Google. That data can have use for prying governments, malicious hackers and Google itself, but Rappor obscures what's actually going on for a given individual before Google even receives the data. The results of the approach, according to the paper, are "strong privacy guarantees."
Why gather user data?
Software companies for years have benefited by gathering data from those who use their products: What's the top cause of crashes? What software features are popular or not? What effect does an interface change have? How many users still have that older operating system?
Typically, software gathers that data and sends it to the software developer, which if it cares about privacy protection has the responsibility of "anonymizing" it so identifying details are removed. With Rappor, which stands for randomized aggregatable privacy-preserving ordinal response, the data is muddled before it's even sent to Google.
Here's how it works, using the paper's example of surveying a population for sensitive information, their membership in the Communist party. A respondent first flips a coin. If it's tails, they answer the question truthfully. If it's heads, though, they say they they are a member regardless of whether they actually are. That muddles the "yes" responses, and another flip can muddle the "no" responses.
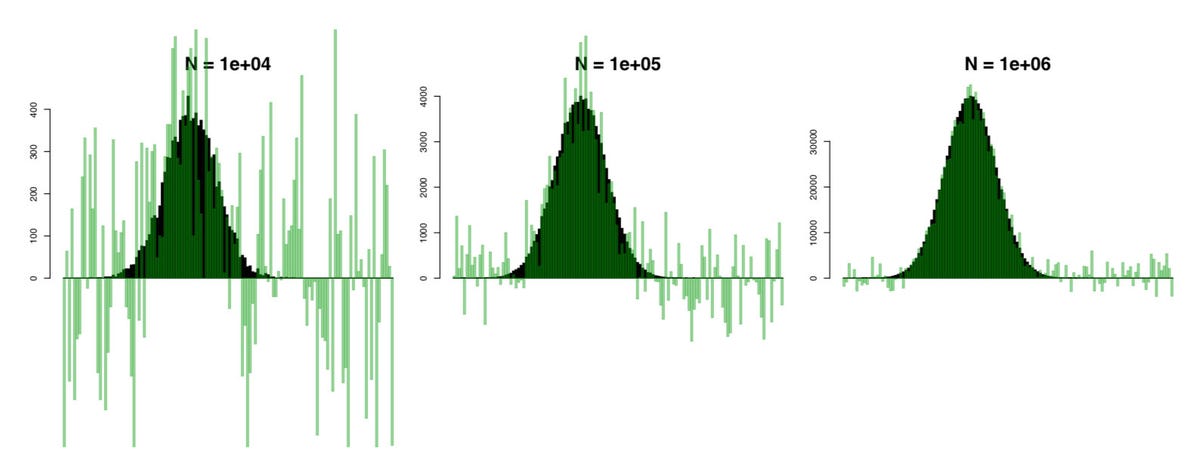
Statistical analysis, of course, can reveal what's going on with the overall population as long as the tested population is big enough. In the case of Chrome, it's vast: there are hundreds of millions of users, though many of them doubtless choose not to send usage data to Google.
Chrome homepage study
The Chrome homepage study reveals a bit more about extracting useful information from the raw data. With the 14 million users monitored, a particular homepage wasn't visible in the statistics until at least 14,000 people were using it. And though the study found 8,616 different homepages being used, only 0.5 percent of them passed that threshold. That small number of Web pages -- something less than 50 -- were very commonly used, though, accounting for 85 percent of the choices people had made.
The randomized response technique has been around for decades, but one problem is that it can reveal personal information if the same person answers the same question repeatedly. The truth eventually shows through the random noise.
Google, though, says Rappor bypasses this problem. One of its accomplishments is "the elegant manner in which [it] protects the privacy of clients from whom data is collected repeatedly," the paper said. Google describes the process, called "memoization," in the paper, cautioning that even randomized data can show patterns over time.
Since it's an open-source project, anyone can build Rappor into their own software. Google is encouraging that: It "puts control over client's data back into their own hands."