The new optimizations for capability computing
The new Top500 list of the world's largest supercomputers suggests that "commodity clusters" for high-performance computing aren't so commodity after all.
This is the time of year to take stock in where high-performance computing (HPC) sits and where it is headed. That's because the SC09 conference is taking place in Portland, Ore., this week and it's the biggest HPC conference around.
SC is an odd duck as conferences go. Last year it had more than 10,000 attendees and, yet, it's a largely volunteer-organized event in a world where trade shows of this scope are packaged by conference specialists or some specific corporation. Think the much-renamed LinuxWorld (run by IDG) or VMworld (run by VMware).
"SC" comes from supercomputing. Today's large computer complexes are typically not supercomputers in the sense of a specialized architecture only suitable for a specific type of technical computing. Rather, as Ashlee Vance notes in The New York Times, "The supercomputing world was long dominated by systems that required specialized chips, memory systems and networking technology. But about 10 years ago, researchers realized they could link thousands of cheaper machines running on mainstream chips and achieve pretty solid performance."
Thus an HPC event is no longer about supercomputers per se (although the term is still used as a convenient moniker for a collection of resources managed as a single entity in a single location). Rather it's about the computing components, the interconnects, the storage, and the software that ties everything together and the applications that run on top.
The Top500 nicely illustrates the evolution of HPC over time. This list, released twice annually, ranks the largest publicly acknowledged supercomputers--as the term is used today--on the basis of a somewhat simplistic, but objective, benchmark. The Top500 entries are certainly not typical of mainstream HPC; they're the biggest of the big. But they nonetheless provide some quantitative insight into important trends.
The newest iteration of the list was released Friday. There were no striking departures from the trends of the last few years, but there was some continued evolution that's worth taking note of.
The continued rise of InfiniBand. InfiniBand is a system interconnect that offers a higher performance alterative to the ubiquitous Ethernet. Although its initial backers envisioned a broader role for the technology, it's settled nicely into HPC and, to a lesser degree, back-end commercial data center functions like database clusters where low latency and high bandwidth are also paramount. (The Sun/Oracle Exadata appliance uses InfiniBand for example.)
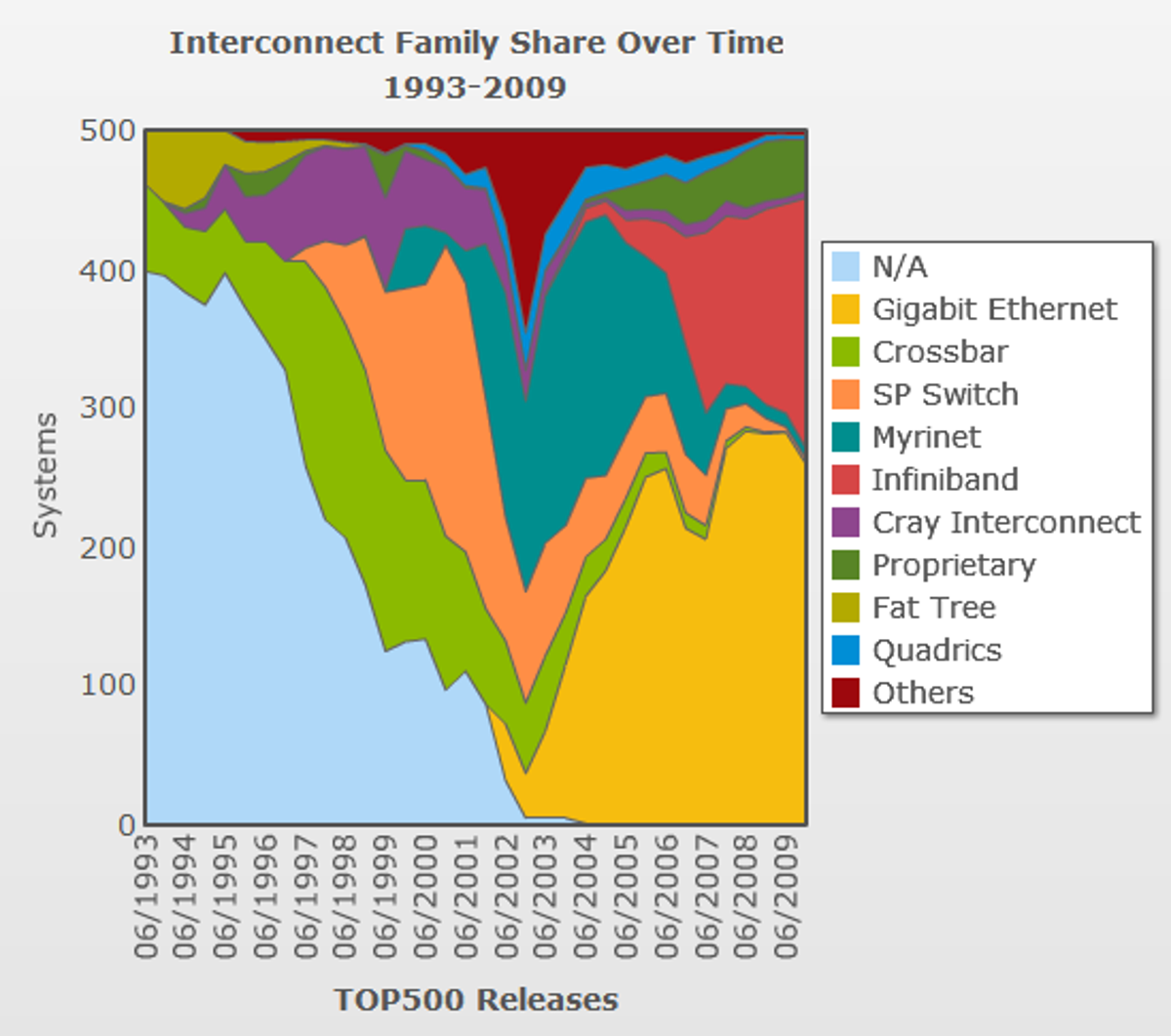
InfiniBand's initial growth in HPC wasn't so much about displacing Ethernet as it was displacing the fractured collection of high-performance interconnects that preceded it. Myricom's Myrinet and Quadrics' QsNet were the most common of these, but there were many. This year InfiniBand is deployed on 181 of the Top500, a 28 percent increase from a year ago.
That's a striking increase clearly. But what is perhaps more striking is that about half that increase came at the expense of Ethernet rather than mopping up a variety of older or proprietary connection technologies. This shift started between 2007 and 2008 but was even more pronounced this year.
It's certainly possible that the next 10GbE generation of Ethernet, which today is essentially absent from the list, could again push Ethernet's numbers higher. However, whatever the specific technology, the message that I take away is that large computer clusters are starting to favor more optimized interconnects even if they and the components they connect are largely off-the-shelf.
And we see an analogous trend with the proliferation of blade servers as well. Blades, a more modular and pluggable approach to system design, have proven popular in many enterprises and midmarket companies, in part, because they help bring together computing, storage, and networking technologies into a single integrated whole. That type of integration isn't of much interest in HPC. Rather, blades play to HPC by offering high densities and reducing cable count and complexity.
In fact, among x86 servers at any rate, dominance is not too strong a word to describe the presence blades in the Top500. Consider just one vendor, Hewlett-Packard. HP has 208 ProLiant systems on the list. A full 203 of these, almost 98 percent, are ProLiant c-Class blades.
Collectively, these trends suggest what might be thought of as a trend toward building optimization around standardization. In the main, especially as one moves down from the very top of the list, the Top500 is composed mostly of systems using mainstream technologies such as x86, Linux, and standard interconnects. Clusters are the dominant architecture.
But we're increasingly not seeing mere rackmount servers connected by Gigabit Ethernet. As the systems on the Top500 list grow in capability, we're seeing more focus on how they're packaged, powered, and connected.