The factor factor, part 2
Ever wonder why new chip designs fail in the market, even though they offer real advantages? Or why others succeed in spite of serious disadvantages? It's apparently due to a secret. Part two of three.
In the first part of this series, I claimed that a great secret in the microprocessor industry largely determines whether new products succeed or fail.
I noted that this secret shouldn't be a secret at all because many people (including myself) have talked about it over the years, but clearly a lot of people are in the dark because they continually disregard it and develop products that are doomed.
I gave several examples of products that failed because their creators didn't know the great secret. Those products included RISC processors, media processors, and intelligent RAM chips, in which processor cores were integrated with memory to eliminate one of the great bottlenecks in computer performance.
During my eight years at Microprocessor Report, I covered the markets for media processors, 3D-graphics chips, network processors, and what I coined extreme processors--chips with large numbers of simple cores running in parallel. Many of these chips were cheaper, easier to design, and twice as fast as competing products--and still failed.
However, some did succeed. The critical factor that made the difference in most of these cases is the essence of the so-called secret.
One of those successes is the graphics processing unit, or GPU.
I was reminded again of the secret at Nvidia's recent GPU Technology Conference, where many of the talks dealt with GPU computing.
(Disclosure: I recently wrote a technical white paper for Nvidia.)
Although the GPU field dates back only five or six years, GPUs have already earned a place alongside CPUs. Each is clearly superior for certain kinds of applications.
This is true in spite of the fact that GPUs aren't nearly as easy to program as CPUs. Like other forms of parallel programming, GPU programming requires new hardware (the GPU itself), significant new extensions for programming languages, and a different mindset for programmers--one that simply wasn't part of standard computer-science curriculum for most of the last 50 years.
Harvard Professor Hanspeter Pfister gave a keynote at the GPU conference, describing several projects in which GPU computing made an essential difference. I'll describe two of them here, but I recommend watching the 90-minute recorded Webcast. It's one of the best presentations I've seen in a while.
Laminated rat brains
One project, being conducted by several organizations, including Harvard's Initiative in Innovative Computing and the Harvard Center for Brain Science, is investigating the so-dubbed Connectome, essentially the "wiring diagram of the brain." Pfister and his collaborators are using GPUs to accelerate computer programs to trace out the exact locations and connectivity of neurons and synapses.
This process starts by taking extremely thin sections of brain tissue from rats using a special device called ATLUM, or Automatic Tape-collecting Lathe Ultra Microtome. The tissue slices from ATLUM are only about 30nm thick, over a thousand times thinner than a hair, small even by comparison with feature sizes in modern integrated circuits.

These slices are laminated to a narrow carrier tape within ATLUM, and these ribbons are attached to six-inch silicon wafers, chosen for their flatness and compatibility with existing wafer-handling equipment.
(This part of the talk immediately reminded me of the classic science-fiction story, "Think Blue, Count Two," in which a character turns a mouse brain into a computer processor by slicing it thin and laminating it in plastic to preserve it and re-establish the neural connections. The story was published in 1962 under the name Cordwainer Smith, a pen name of Paul M. A. Linebarger, a godson of Sun Yat-sen and author of the seminal text "Psychological Warfare." Linebarger was truly a remarkable man, and in my opinion, the most imaginative science-fiction writer of all time.)
The wafers are then scanned using electron microscopes to produce images of the cellular structure and the images are merged to create gigantic three-dimensional databases.
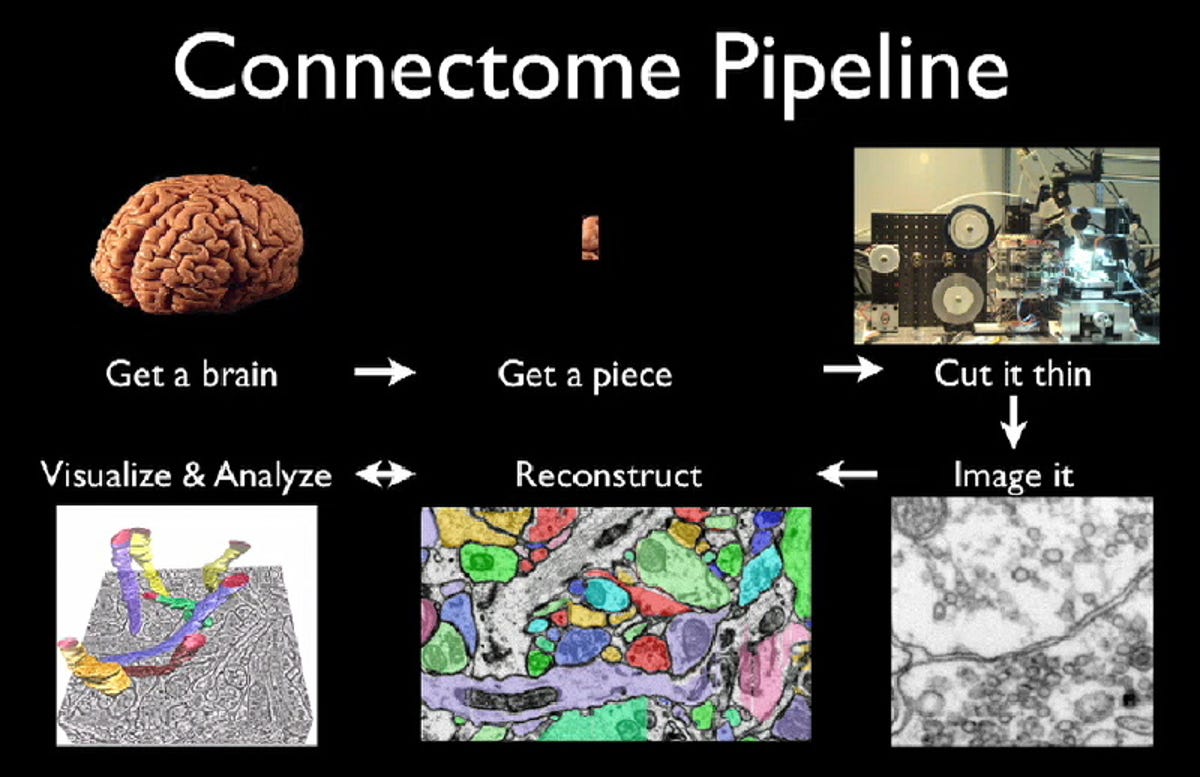
One cubic millimeter of brain tissue will fill 20 of these wafers. Scanned at a resolution of 5nm per pixel, that cubic millimeter of tissue will produce about 1.5 petabytes of data, comparable to the total volume of user photos stored on Facebook.
And that's still only enough to record the full structure and connectivity of just a few neurons.
Once this data is collected, it has to be interpreted. The cell boundaries aren't very clear, so very sophisticated image processing is required along with human interaction to guide the process.
Pfister found that performing this processing on GPUs instead of CPUs provided a 23x speedup, allowing a fairly natural workflow. A scientist identifies cell boundaries and the software follows the boundaries, with the scientist correcting any recognition errors.
To date, this work has involved only small samples of brain tissue; scaling it up to larger volumes, which is necessary to gain a full understanding of how brains work in a practical way, will require much larger compute arrays. Without the higher performance of the GPU implementation, this whole process would be impractical--either too slow or too expensive.
Radio astronomy on 20 kilowatts
Another project described by Pfister is the Murchison Widefield Array (MWA), a new kind of radio telescope that uses fixed, low-cost antenna arrays to produce massive amounts of data that are mathematically correlated and integrated to produce images.

One of the critical issues in this application is that the antenna array must be located far away from terrestrial radio sources, which means: away from power sources. In fact, the whole system runs on a single 20-kilowatt diesel generator. According to a paper published on the role of GPUs in the Murchison Widefield Array, the system would have required 100 Intel Xeon processors in systems consuming a total of 30 kW. A much smaller array of GPUs, on the other hand, can perform the work within the power budget.
Of course, a larger generator could have been used, but a rack or two of servers would have required a larger air conditioner, at least, and probably a larger trailer. Even if that wasn't practical, multicore CPU technology eventually would have advanced to the point of enabling this project. Still, it was quicker for the scientists to code their algorithms for the unique requirements of GPU computing than to wait for CPUs to speed up.
These examples show why GPUs succeeded whereas media processors failed, becoming only the second general-purpose computing resource on the mainstream PC platform.
The difference is explained, at least in part, by my secret rule. Have you guessed what it is yet? If not, check out Part 3 and I'll explain.