Library of Congress test drives cloud storage
A new cloud project to share and replicate data is being tested by the Library of Congress and other institutions. Maybe a new world of data sharing is upon us.


The Library of Congress National Digital Information Infrastructure and Preservation Program and DuraSpace have announced that they will launch a one-year pilot program to test the use of cloud technologies to enable perpetual access to digital content.
The pilot will focus on a new cloud-based service called DuraCloud, that replicates and distributes content across multiple cloud providers and enables organizations to share, access, and preserve said content. Eventually the service will also provide computing capabilities in addition to the storage and archiving functions. (DuraSpace is a joint effort of the Fedora Commons and the DSpace Foundation.)
The project started with a vision of federated repositories and infrastructure that would scale massively and remove the risks of data silos. The other major goal is to make the service usable across external and internal cloud deployments.
Let's assume that any security issues can be worked out and recognize that this approach may actually be the ideal way for government agencies to share and archive data--especially data that's not terribly sensitive.
Just the ability to share data across agencies and with the public would be a huge advancement for any agency. Based on the architecture diagram below, this looks like a feasible approach--at least until agencies start building internal clouds that become silos (again).
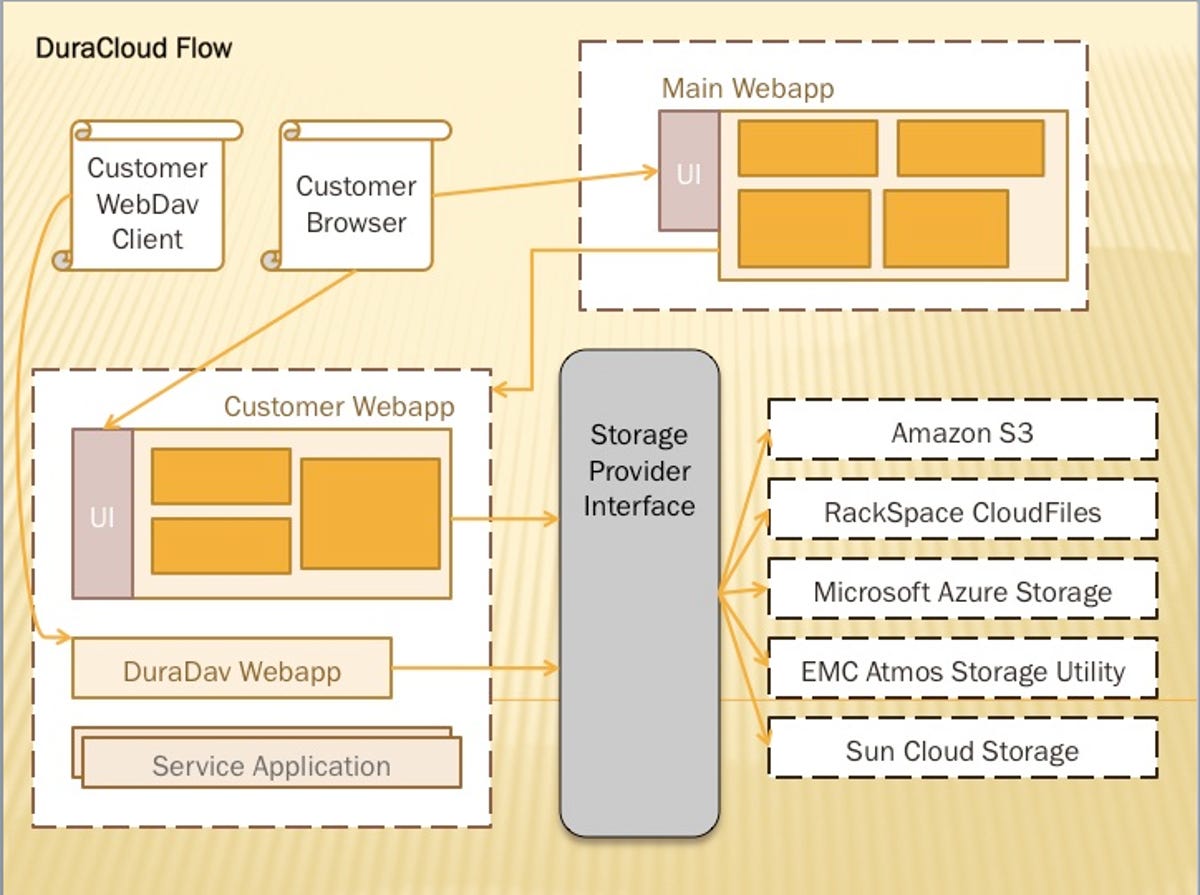
Among the NDIIPP partners participating in the DuraCloud pilot program are the New York Public Library and the Biodiversity Heritage Library.
There are plenty of these kinds of efforts under way and sooner or later one will hit the mark. I look forward to the day when the cloud promise fully delivers.
Follow me on Twitter @daveofdoom.