Why You Can Trust CNET
Why You Can Trust CNET Amazon launches Hadoop data-crunching service
Customers can use MapReduce to pay by the sip as they do things like index the Web, mine data, and conduct financial analysis or bioinformatics research.


This was originally posted at ZDNet's Between the Lines.
A correction has been made to this story. See details below.
Amazon on Thursday announced a new cloud computing service that uses Hadoop, a free software framework, to crunch tons of data.
The service, called Amazon Elastic MapReduce, is designed for businesses, researchers and analysts trying to conduct data intensive number crunching (statement). Hadoop, which is used by companies like Yahoo, is trying to be pushed into the enterprise data center by start-ups like Cloudera.
Correction, 7:15 a.m. PDT: This story initially miscast Google's connection to Hadoop. Google invented and uses the MapReduce technology, but it doesn't use Hadoop, an open-source implementation of MapReduce. At least it doesn't use it broadly. It has its own in-house version.
Amazon's Hadoop framework runs on the company's Elastic Compute Cloud (EC2) and Simple Storage Service (S3). The general idea is that customers can use MapReduce to pay by the sip as they do things like index the Web, mine data, conduct financial analysis, simulation and bioinformatics research.
In its statement, Amazon said:
Amazon Elastic MapReduce creates data processing job flows that are executed by Hadoop software on the web-scale infrastructure of Amazon EC2. The service automatically launches and configures the number and type of Amazon EC2 instances specified by customers. It then kicks off a Hadoop implementation of the MapReduce programming model, which loads large amounts of user input data from Amazon S3 and then subdivides it for parallel processing using Amazon EC2 instances. As processing completes, data is re-combined and reduced into a final solution, and the results deposited back into Amazon S3. Users can configure, manipulate, and monitor job flows through web service APIs or via the AWS Management Console.
That roughly translates to: Bring your data mining to us.
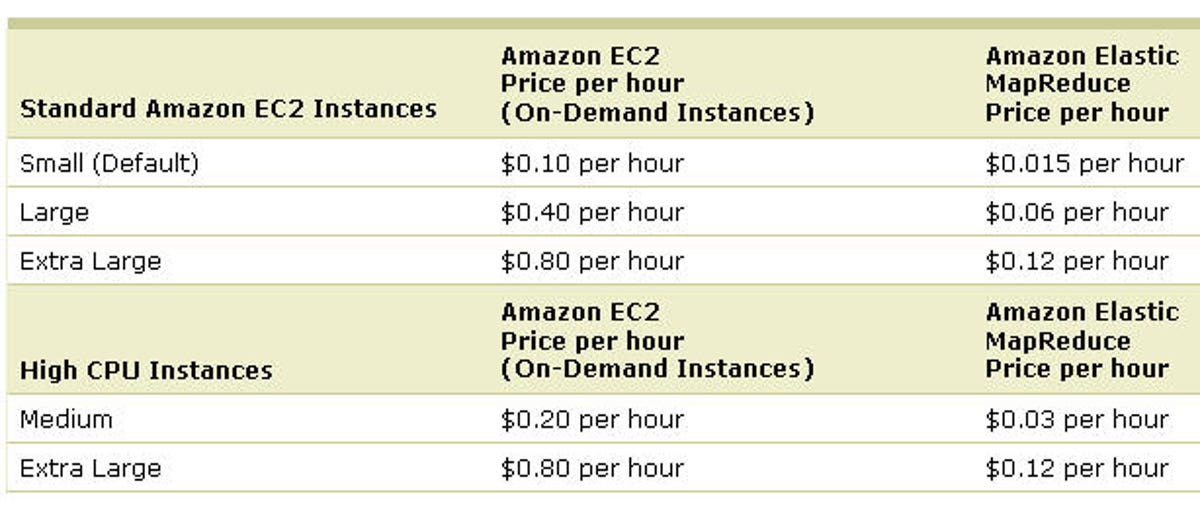
MapReduce is a separate service and here's the pricing in the U.S.: