Where IT is going: Cloud, mobile, and data
Today's IT world is changing dramatically because of the convergence of cloud computing, mobility, and everything else associated with running apps on the Web, and big data.
Cloud computing seems to often get used as a catch-all term for the big trends happening in IT.
This has the unfortunate effect of adding additional ambiguities to a topic that's already laden with definitional overload. (For example, on a topic like security or compliance, it makes a lot of difference whether you're talking about public clouds like Amazon's, a private cloud within an enterprise, a social network, or some mashup of two or more of the above.)

However, I'm starting to see a certain consensus emerge about how best to think about the broad sense of cloud, which is to say IT's overall trajectory. It doesn't have a catchy name; when it's labeled at all, it's usually "Next Generation IT" or something equally innocuous. It views IT's future as being shaped by three primary forces. While there are plenty of other trends and technology threads in flight, most of them fit pretty comfortably within this framework.
The three big trends? Cloud computing, mobility, and "big data."
Through the lens of next-generation IT, think of cloud computing as being about trends in computer architectures, how applications are loaded onto those systems and made to do useful work, how servers communicate with each other and with the outside world, and how administrators manage and provide access. This trend also encompasses all the infrastructure and "plumbing" that makes it possible to effectively coordinate data centers full of systems increasingly working as a unified compute resource as opposed to islands of specialized capacity.
Cloud computing in this sense embodies all the big changes in back-end computation. Many of these relate to Moore's Law, Intel co-founder Gordon Moore's 1965 observation that the number of transistors it's economically possible to build into an integrated circuit doubles approximately every two years. This exponential increase in the density of the switches at the heart of all computer logic has led to corresponding increases in computational power. (Although the specific ways that transistors get turned into performance has shifted over time.)
Moore's Law has also had indirect consequences. Riding Moore's Law requires huge investments in both design and manufacturing. Intel's next-generation Fab 42 manufacturing facility in Arizona is expected to cost more than $5 billion to build and equip. Although not always directly related to Moore's Law, other areas of the computing "stack" -- especially in hardware such as disk drives -- require similarly outsized investments. The result has been an industry oriented around horizontal specialties such as chips, servers, disk drives, storage arrays, operating systems, and databases rather than, as was once the case, integrated systems designed and built by a single vendor.
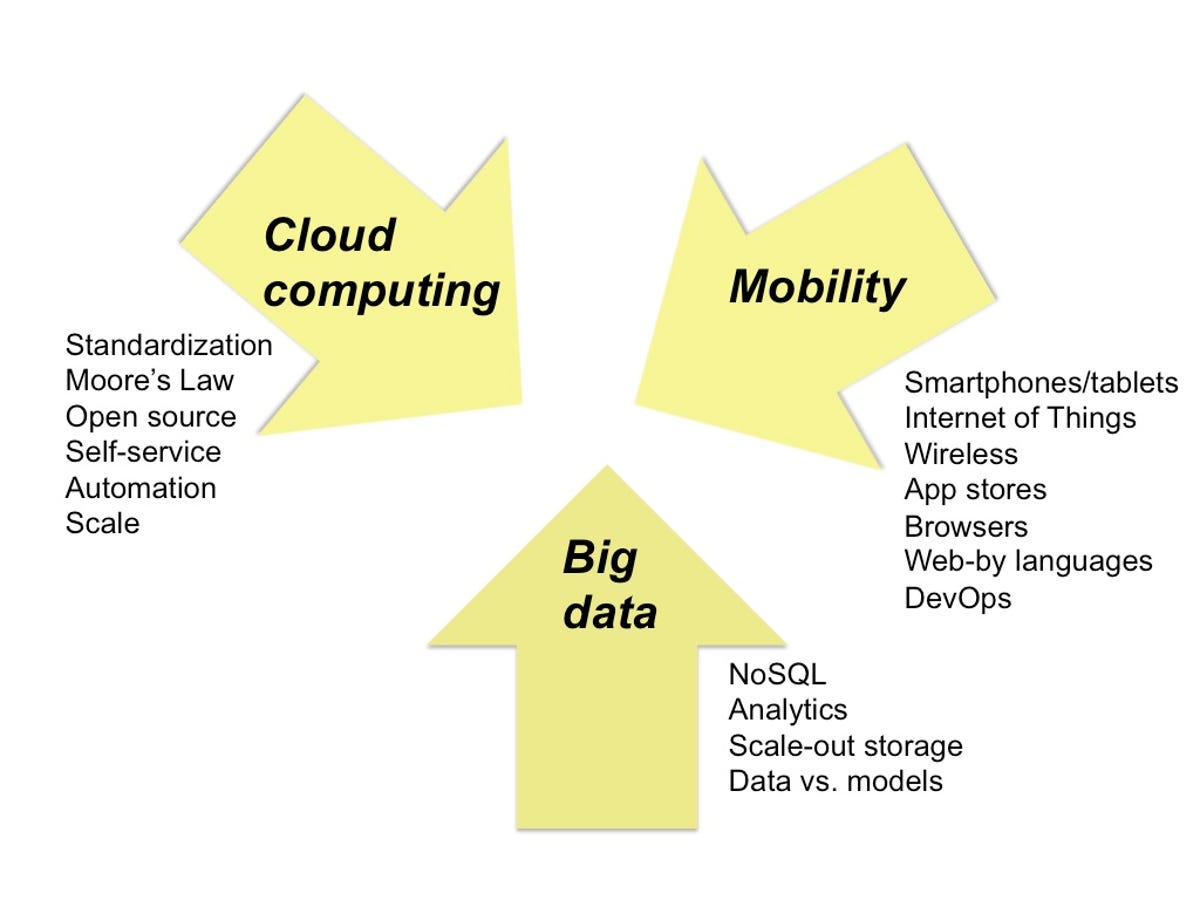
This industry structure implies standardization with a relatively modest menu of mainstream choices within each level of the stack: x86 and perhaps ARM for server processors, Linux and Windows for operating systems, Ethernet and InfiniBand for networking, and so forth. This standardization, in concert with other technology trends such as virtualization, makes it possible to create large and highly automated pools of computing that can scale up and down with traffic, can be re-provisioned for new purposes rapidly, can route around failures of many types, and provide streamlined self-service access for users. Open source has been a further important catalyst. Without open source, it's difficult to imagine that infrastructures on the scale of those at Google and Amazon would be possible.
The flip side of cloud computing is mobility. If cloud computing is the evolved data center, mobility is the client. Perhaps the most obvious shift here is away from "fat client" PC dominance and towards simpler client devices like tablets and smartphones connecting through wireless networks using Web browsers and lightweight app store applications. This shift is increasingly changing how organizations think about providing their employees with computers, a shift that often goes by the "Bring Your Own Device" phrase.
However, there's much more to the broad mobility trend than just tablets and smartphones. The "Internet of Things," a term attributed to RFID pioneer Kevin Ashton, posits a world of ubiquitous sensors that can be used to make large systems, such as the electric grid or a city, "smarter." Which is to say, able to make adjustments for efficiency or other reasons in response to changes in the environment. While this concept has long had a certain just-over-the-horizon futurist aspect, more and more devices are getting plugged into the Internet, even if the changes are sufficiently gradual that the effects aren't immediately obvious.
Mobility is also behind many of the changes in how applications are being developed -- although, especially within enterprises, there's a huge inertia to both existing software and its associated development and maintenance processes. That said, the consumer Web has created pervasive new expectations for software ease-of-use and interactivity just as public cloud services such as Amazon Web Services have created expectations of how much computing should cost. The Consumerization of Everything means smaller and more modular applications that can be more quickly developed, greater reliance on standard hosted software, and a gradual shift towards languages and frameworks supporting this type of application use and development. It's also leading to greater integration between development and IT operations, a change embodied in the "DevOps" term.
The third trend is big data. It's intimately related to the other two. Endpoint devices like smartphones and sensors create massive amounts of data. Large compute farms bring the processing power needed to make that data useful.
Gaining practical insights from the Internet's data flood is still in its infancy. Although some analysis tools such as MapReduce are well-established, even access to extremely large data sets is no guarantee that the results of the analysis will actually be useful. Even when the objective can be precisely defined in advance -- say, improve movie recommendations -- the best results often come from incrementally iterating and combining a variety of different approaches.
Big data is also leading to architectural changes in the way data is stored. NoSQL, a term which refers to a variety of caching and database technologies that complement (but don't typically replace) traditional relational database technologies, is a hot topic because it suggests approaches to dealing with very high data volumes. (Essentially, NoSQL technologies relax one or more constraints in exchange for greater throughput or other advantage. For example, when you read data, what you get back may not be the latest thing that was written.) NoSQL is interesting because so much of big data is about reading and approximations -- not absolute transactional integrity as with a stock purchase or sale transaction.
All this data is also physically stored differently. Just as high-value transactions are processed so as to minimize failure or mistakes, so too is the associated data stored on arrays of disks using high-end parts and connected using specialized networks. But these come at a high cost and, anyway, they're not really designed to scale out to very large-scale distributed computing architectures. Thus, big data is increasingly about scale-out software-based storage that spreads out along with the servers processing the data. We are effectively circling back to a past when disks were all directly attached to computer systems -- rather than sitting in centralized storage appliances. (Of course, the scale of both computing and storage is far, far greater than in those past times.)
Computing is always evolving of course. However, what makes today particularly interesting is that we seem to be in the midst of convergent trends of a certain momentum and maturity to reinforce each other in significant ways. That's what is happening with cloud computing, mobility, and big data.