Use the tools that make the job easier
Google recently discussed one of its smart strategies for dealing with the tremendous diversity found on the Web: up-leveling whatever data it finds into a higher level representation.


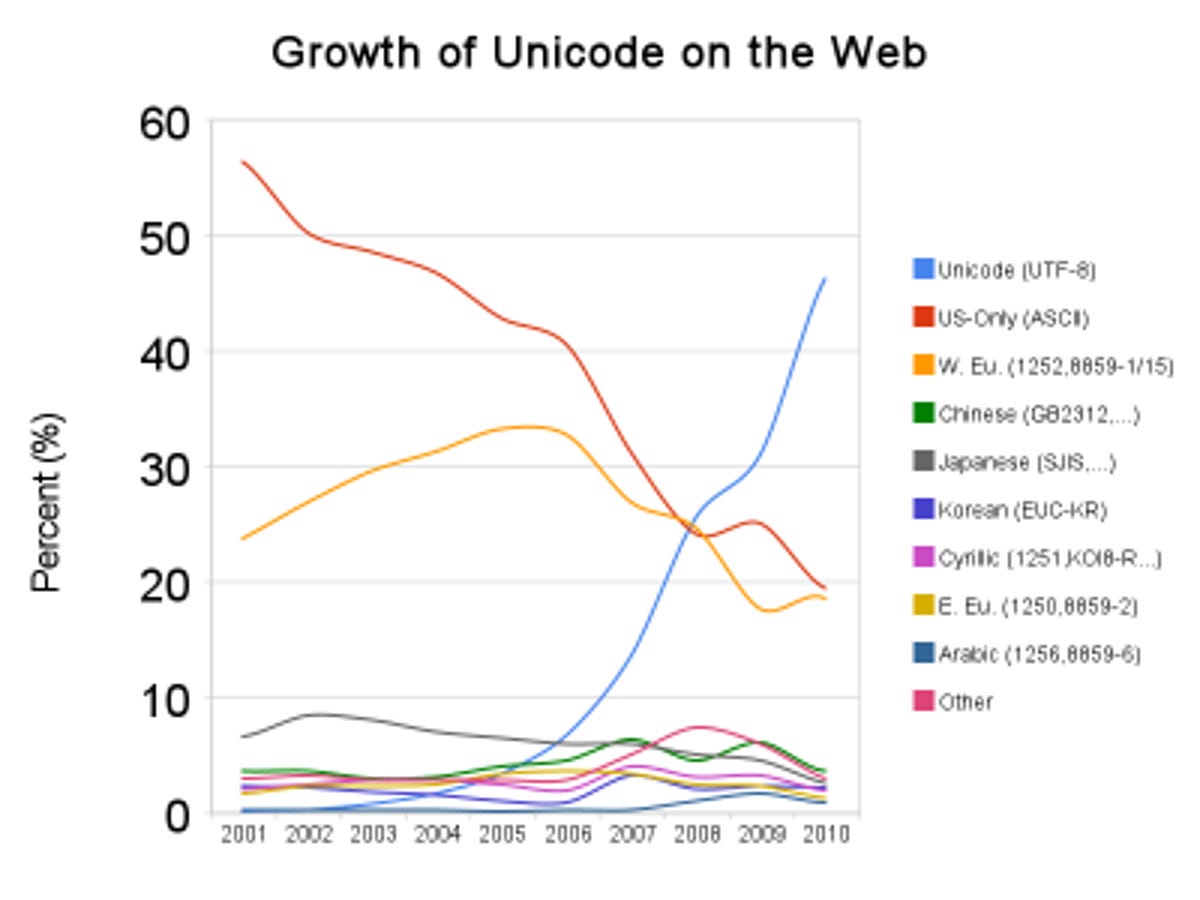
Google recently published data showing that the character encoding used on the Web is dramatically shifting towards the Unicode standard. It also discussed its strategy of up-leveling data it finds in dozens of competing character encodings into the Unicode standard, then processing everything in Unicode. This is a great example of the philosophy:
- Use tools that make the job easy.
When you narrow the field to data formats and structures, you can make the rule a bit more specific:
- Use data formats that are easy to process.
- Convert to and from those formats, if and as necessary.
And for good measure, you could throw in a kicker:
- The ideal formats are rich, flexible, standardized, open, widely supported, and efficient.
In the olden times, this advice would be laughed at. System resources were scarce and expensive, so everyone did everything possible to minimize the hardware resources used. Architects and programmers felt an pressing obligation to optimize, optimize, and optimize some more.
And even though there are vastly more IT workers than there were a few decades back, the scale of global computing and communications enabled by IT has grown so much faster that we don't have nearly enough people. We have to scale IT operations much more effectively than in years past. That means we need to build applications much more quickly--and to update them over time much faster, at much lower cost.
This is where flexible, high-level, standardized, easy-to-process data formats come into play. Sure, many programming languages, programs, libraries, APIs, database engines, and such have had to be updated over the years to support the Unicode standard--and that wasn't always smooth sailing. But mostly they now have been, so essentially every human language and character encoding you might find can be accommodated by mapping it into Unicode. If you process in Unicode, you only have to do things once--not dozens of times. One toolset. One skillset. One codebase. Yes!
This kind of leverage is available not just in Unicode, but a variety of high-level formats that have become popular over the last decade: XML (and numerous domain-specific XML-based languages), XHTML, YAML, and ODF, to name just a few. The ZIP format is now widely used, superseding dozens of historical archive formats. While the situation in multimedia formats remains complex, a handful of standards such as JPEG, PNG, and SVG have gradually edged out scores of much narrower antecedents. Even virtual machine (VMs) can be seen in this light; software that was once bound to specific hardware, embedded in a VM, can be studied, updated, stored, or run in a variety of places, independent of the hardware.
None of these is up-leveled formats is perfect or universal, but compared to the ugly alternative of managing lower-level, narrower, piecemeal alternatives--and possibly, dozens of them--we can only give thanks.
Because we have ever less time to build apps and services, and because the human resources needed to get the job done are now the gating factor (not system resources), there aren't too many good counter-arguments to the idea of up-leveling our data and tasks, then using the most powerful tools we can find. Google's Unicode data shows that when the higher-level formats become the the standard, you no longer even need to translate so much. Leverage--it's a beautiful thing.