IBM Research jumps into genetic sequencing
Big Blue hopes its electronic automation technology will give people and their doctors individual genetic records for less than $1,000.


- Shankland covered the tech industry for more than 25 years and was a science writer for five years before that. He has deep expertise in microprocessors, digital photography, computer hardware and software, internet standards, web technology, and more.
It took 13 years for researchers to catalog all the information in a human genome the first time. Now IBM believes it can do better--somewhat perversely by equipping a newer genetic sequencing method with brakes.
Big Blue is among those who believe electronics technology can be applied to the task of sequencing a person's genes, thereby bringing genetic testing into the computing era and lowering its cost to something like $100 to $1,000.
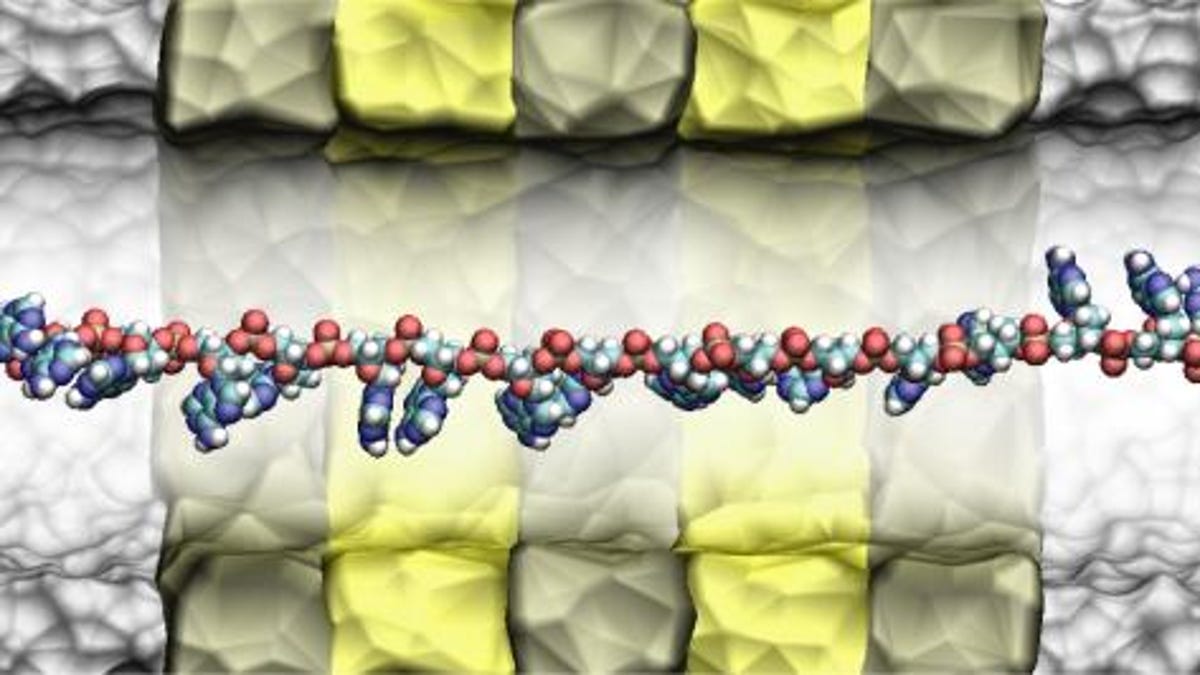
IBM is working on prototype DNA-processing electronics that slurps strands of DNA through an extremely small hole called a nanopore, measuring the electrical properties of the chemicals as they go by to determine the genetic information. That technique is used beyond IBM, but what Big Blue researchers have been working on is a way to slow down, an essential step toward improving its precision, said Gustavo Stolovitzky, manager of the IBM Functional Genomics and Systems Biology Group.
IBM Chief Executive Sam Palmisano is scheduled to unveil the project and what the company calls its "DNA transistor" Tuesday in a talk, "IT Innovation in Healthcare," at the Cleveland Clinic, IBM said.
The ultimate goal for such research is affordable genetic sequencing. "It would allow DNA sequences to be more or less routine," Stolovitzky said, forecasting that the technology will arrive in five or ten years.
OK, but why should you care?
"It would enable the possibility of going to the doctor with some infection, and the doctor gets the sequence pretty much on spot of the bacteria affecting the patient or the virus is in the blood," Stolovitzky said.
Or another possibility: knowing patients' specific genotypes could mean doctors would know if they had a negative reaction to some drug. That could mean some drugs useful that today are banned could become useful to a subset of the population.
IBM isn't the only one working on this technology. In addition to various academic efforts, start-up 23andMe offers some genetic analysis today.
The genes of animals and plants are encoded in DNA with just four molecular-scale substances--adenine, thymine, guanine, and cytosine. Their particular order governs not only their the formation of humans and other organisms but also the day-to-day biochemistry that keeps us alive.
IBM's sequencing technique to transcribe this biochemical data has been under way for three years, and it's easier said than done. The company is in the process of creating a new prototype device updated to reflect what IBM learned from an earlier one that didn't work as hoped.
"Translocation control we should have in a year's time more or less," Stolovitzky said, referring to the ability to ease the DNA through the nanopore one pair at a time.
The distance scales alone make the work difficult. Each DNA base is about 5 or 6 angstroms away from its neighbor--about half a billionth of a meter. By comparison, a human hair is colossal, about a ten-thousandth of a meter in diameter. And the DNA strands slip through a nanopore that's 2 to 3 billionths of a meter wide.
One problem with the nanopore approach is that it's hard to distinguish the four substances, called bases, as they slip through the hole. The four bases have overlapping electrical properties, so the more time spent measuring each, the better the accuracy.
IBM's approach uses a flat device about 250 nanometers on a side. It has very thin alternating layers of metal and a material called a dielectric. The nanopore is bored through these layers using an electron beam from a tunneling electron microscope, Stolovitzky said.
On one side of the layer is the DNA, unzipped from its familiar double-helix configuration with two strands of matched bases into a single strand with single bases. The single-strand is important in part because the distance between each pair increases to between 5 and 6 angstroms, making them more manageable than the double strand with bases 3.4 angstroms apart, he said.
The strand is pulled through the nanopore by an electrical field that attracts the negatively charged strand. But in the nanopore, some layers are electrically switched on to fix the strand in place for a tick of an electronic clock while another layer makes its measurement, Stolovitzky said.
Even slowed down, the process is fast compared with humans toiling away with pipettes and polymerase chain reaction equipment in a lab. "We think 1 millisecond should be a reasonable time to measure (a base)," Stolovitzky said. In other words, it would take about a second to perform 1,000 measurements.
The human genome has about 3 billion base pairs, so that's still a lot of time to do a full analysis. But it's sill more complicated because the chromosomes that house the genetic data must be broken up into smaller strands for practical reasons.
But IBM Research is happy to pursue a number of projects that may not pay off immediately, including work touching on nanotechnology, computing, and biotechnology. Whether it'll all come to fruition remains to be seen, but one way or the other, it's likely you'll know your own genetic data within a matter of years.