Google: Unicode conquers ASCII on the Web
Unicode outpaces ASCII for encoding Web site text, and life gets easier for Google and others that grapple with an increasingly international Internet.


- Shankland covered the tech industry for more than 25 years and was a science writer for five years before that. He has deep expertise in microprocessors, digital photography, computer hardware and software, internet standards, web technology, and more.
I picture it happening this way. The Roman alphabet is on the run, pursued by a much larger army of Arabic characters with long scimitar-like ligatures, Chinese characters that look like throwing stars, and European peasant letters bristling with umlauts, cedillas, and tildes.
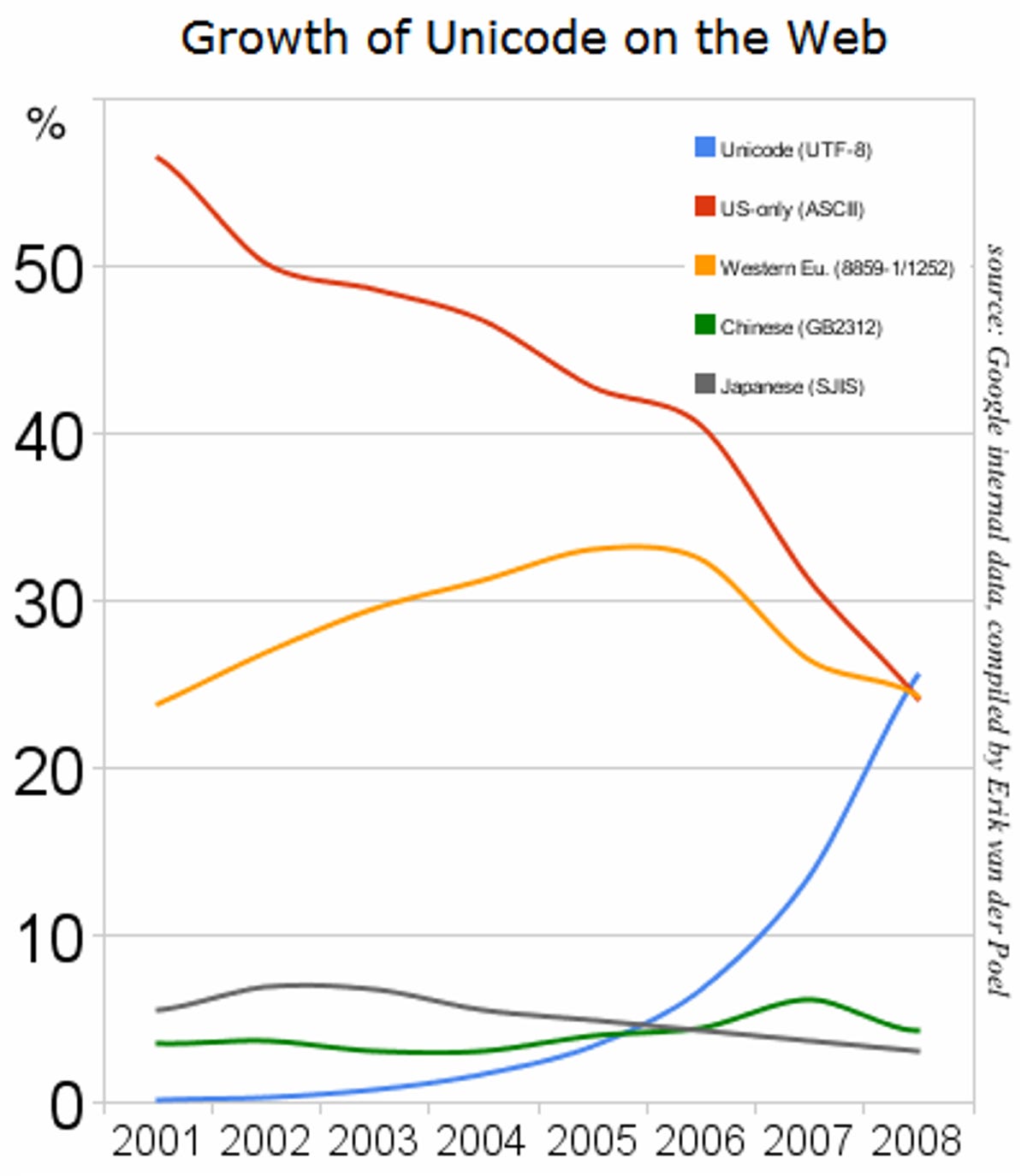
Unicode has overtaken ASCII as the most popular character encoding scheme on the World Wide Web, Mark Davis, Google's senior international software architect, said in a blog post. Also vanquished at almost exactly the same time was the Western European encoding.
Unicode is a character encoding standard that gracefully accommodates dozens of languages as well as Roman characters with diacritical marks. ASCII, a tried-and true, decades-old standard, is limited to 128 or 256 characters and has a hard time extending beyond the range of a century-old Remington typewriter.
Unicode vanquished ASCII and Western European within 10 days in December, Davis said.
"What's more impressive than simply overtaking them is the speed with which this happened," he added, pointing to a graph showing the meteoric rise of Unicode.
Google's a fan of Unicode Web sites. When it processes data from Web sites, it converts it into Unicode first if it's not already there. That improves international search abilities.
"The continued rise in use of Unicode makes it even easier to do the processing for the many languages that we cover," he said.
Google just converted to Unicode 5.1, he added, "so people speaking languages such as Malayalam can now search for words containing the new characters," he said.
One disadvantage Unicode has over ASCII, though, is that it takes at least twice as much memory to store a Roman alphabet character because Unicode uses more bytes to enumerate its vastly larger range of alphabetic symbols.