Google censors 'Lolita,' but not 'bestiality'
Following revelations that cell phones running on Android replace rude words with hash marks, it appears that works such as "Lolita" and "Best Little Whorehouse in Texas" are also censored.


It seems like only yesterday that news surfaced that naughty words were being replaced by hash marks on Android phones.
Should you have missed this purely puritan entertainment, words such as the very common one beginning with an "f" were being censored by the built-in voice-to-text feature found on Google's mobile operating system. Even the latter half of "BS" became "####".
This appears, however, not to have been the half of it. CNET's readers are nothing if not disturbingly intelligent. And I am particularly grateful to Zechariah-Aloysius Hillyard from Boston who put his Droid and his patience through their paces in the quest for, well, accursed freedom.
Hillyard was surprised to find that a search for "Nabokov Lolita" became "Nabokov ####" when transcribed by Google Voice (safe search was switched off). This seemed strangely picky of the software, especially as Hillyard told me he tried the search after enjoying "Reading Lolita in Tehran," a book that itself wonders what should be acceptable and what not.
So, encouraged by my own curiosity, he delved further. "Ass" seemed to be acceptable. However, "Oh, Come All Ye Faithful" became "Oklahoma, All Ye Faithful," followed by "#### All Ye Faithful."
"Scum" and "Scumbag" appeared to encounter a huge hash of resistance, although the second time he tried "Scumbag," he got "Futurama" (the cartoon).
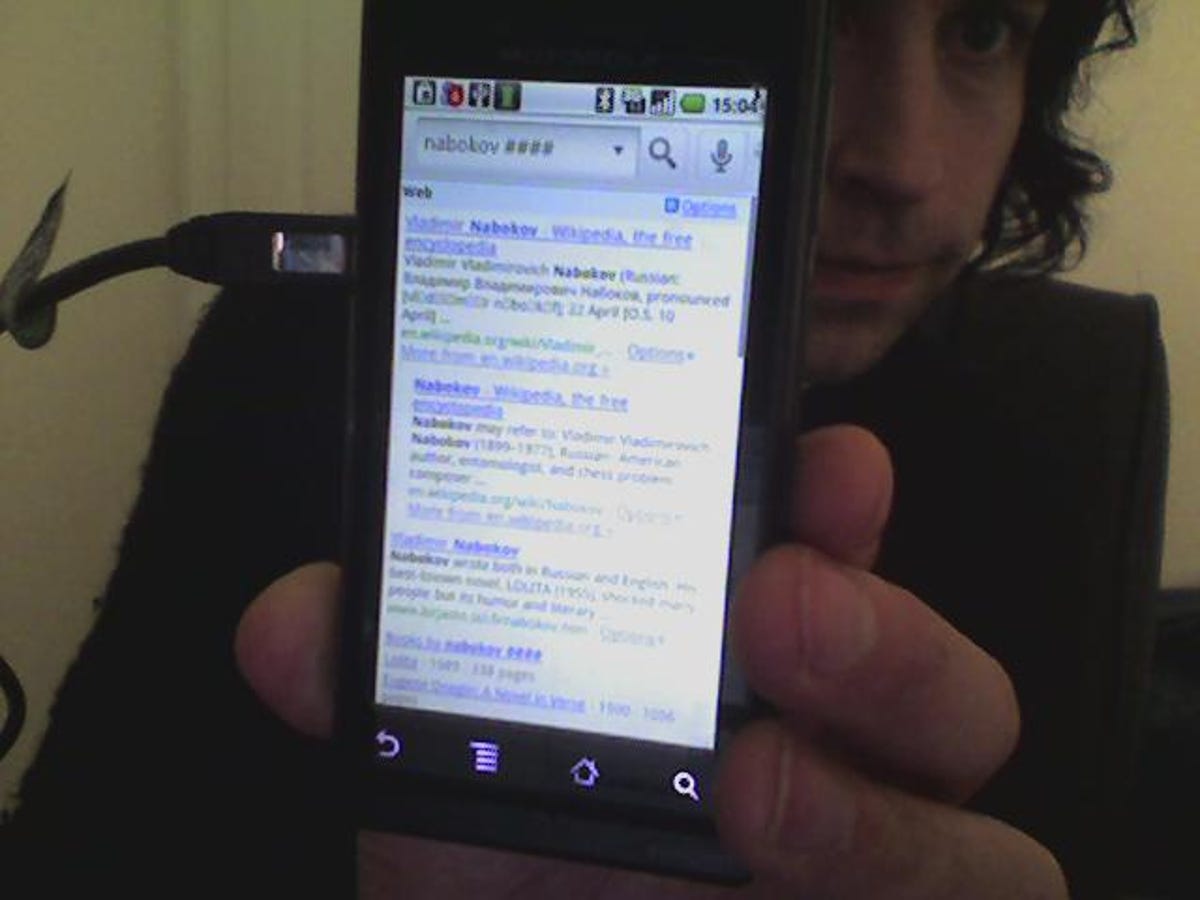
"I wonder how many #### words there are," Hillyard told me in an e-mail. "The arbitrariness of it bothers me as an American and as a curious person. Do I get my phone service terminated if I get too many ####'s?"
Any fear he might have experienced quickly dissolved as he began to delve further into the Android underworld.
"Incest" was hashed, but "bestiality" was fine. And if you're wondering what other works of literature might have been made a hash of by Android, well, you may be relieved to hear that "Lady Chatterley's Lover" enjoyed no censorship. However, "Best Little Whorehouse in Texas" was a vast no-no.
Google's original explanation for this phenomenon to Reuters went as follows: "We filter potentially offensive or inappropriate results because we want to avoid situations whereby we might misrecognize a spoken query and return profanity when, in fact, the user said something completely innocent."
I would be interested if other readers have experienced similarly innocent linguistic peculiarities. However, is it really likely that any human or machine would misrecognize "Lolita"? Especially when it is uttered in the very close juxtaposition to a word that sounds mightily like "Nabokov"?
I understand censorship. We all censor ourselves every day. But did Google's engineers really sit around and make value judgments about what might be misrecognized and what might not?
I have already asked Google twice to further enlighten its customers on this very interesting encounter between technology and moral philosophy, one that is certainly more fascinating than anything currently on TV. I have yet to receive a reply.