Google bringing new smarts to search with Knowledge Graph
Search giant builds a 500-million-item database of people, places, and things. Its content will be appearing in your search results starting today.



Google has long sought to index the world's information -- and it's now taking things a step farther with an effort to create "a database of everything in the world." And it's bringing this effort to your search results pages.
The new Knowledge Graph project, rolling out to English-language Google Search users over the next few days, provides more data snippets alongside its query results than the search engine currently provides. The results are based on Google's new database of 500 million people, places, and things, says Jack Menzel, Product Management Director of Search at Google. Menzel says there are 3.5 billion attributes and connections between these things in the database.
You'll be able to meander through lists of facts and connections when you are searching for items that are in the Knowledge Graph. As one Google example illustrates, if you search for Frank Lloyd Wright, you'll get a fact box with a summary about him (from Wikipedia), a small collection of biographical facts, and picture links to the buildings he designed. If you click on Fallingwater, you'll get another fact box about that house.
Google has both personnel and technology to curate what results appear in these fact boxes.
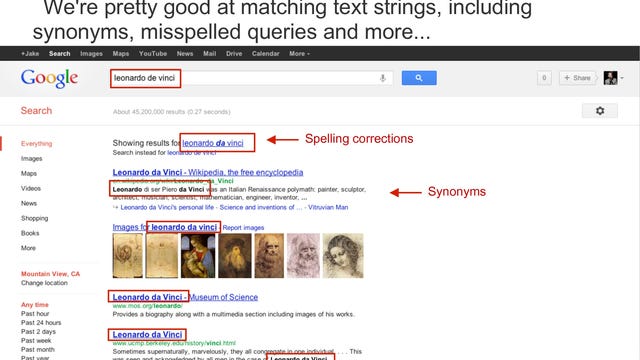

The new, fact-enabled Google will also help you disambiguate search results. If you're looking for "Kings," for example, Google will guess that you might be referring to the hockey team, the NBA team, or the TV show, and you'll have the opportunity, alongside the usual search results, to select one of those topics to narrow down your search results.
Menzel says that before the rollout of Knowledge Graph, Google didn't reflect any "knowledge that a word refers to anything in the world." While some keywords would fire off specialized results with data in them (like searching for a sports score, a city's weather, or flight information), those results weren't linked together in a web of knowledge. They were islands. Knowledge Graph changes that.
"We would like to be able to model everything," says Menzel. "Anything to get you to the information that solves your task as fast as we can. We want to guide you through your query a bit like a map."
Stealing traffic?
Google, of course, is built on top of the open Web of sites and pages. That's where Google gets its data and it's also the information economy that Google supports. Knowledge Graph provides data to users without requiring them to go to the sites that the data may come from. One might deduce that Knowledge Graph would end up hurting sites by stealing traffic from them.
Menzel says that's not the case. "We found that by doing better information summaries, the vast majority of the time people don't just get facts and walk away. Actually, it entices them to go a little deeper. And now they have the time for it since their research was faster."
He does acknowledge that in some cases, the most satisfactory outcome to a user's search may be a Knowledge Graph data point. "We want to point people to the most relevant info. Occasionally that is just a fact." He says it's Google's mission to get people those facts as quickly and efficiently as possible. But it's against mission to harm Web publishers. "We really respect the ecosystem. It makes no sense for us to obviate the Web," he says.
Not the first online knowledge engine
Other companies have tried to add context to search results. There's also a rich history of startups who have tried to "understand" Web pages. Powerset is one; it was acquired by Microsoft. And then there was the unfortunate failure of Cuil.
Even Google has previously tried to create a database of things, as opposed to simply an index of Web pages. In 2010, Google acquired Metaweb, the creator of the knowledge base Freebase. Menzel says Freebase is one of the most important "concept cars" from Google's past that ultimately became the Knowledge Graph.
Tech from Google's Squared labs project also ended up in Knowledge Graph. Squared attempted to extract structured data from non-structured Web pages.
Google has also tried its hand at creating its own topic dossiers before: The Knol project was conceptually similar to Wikipedia. It was discontinued in late 2011.
As far as the disambiguation technology in Knowledge Graph, Menzel points to the technology behind the search query spelling corrector as "the ultimate grandfather of all this."
What this latest knowledge extraction and display project brings to search users, Menzel says, is "comprehensiveness and sheer volume." Also, he points out that Google will show just that data that is most relevant to a query, making use of Google's expertise in ranking search results.
Menzel pitches Knowledge Graph without using the word "semantic" even once. While he says, "I dream of the semantic Web," he takes pains to point out that what Google is announcing today is not what people talk about when they discuss semantic Web concepts. "We do continue to work on how to make search semantic," he says, "but talking about it brings out the crazy people."