Big data in context
A whole realm of new vendors aim to make it easier to process vast amounts of information. It's a field that's as interesting as it is complicated.


A few weeks back I attended venture firm Accel Partners' New Data Workshop event and learned quite a bit about the state of what we are now commonly referring to as "big data" and the challenges that await the vendors trying to target this new way of slicing and dicing vast amounts of information.
One of the big takeaways for me was the realization that even with all of the processing power available nowadays, the amount of data is growing at such a rapid pace that people are simply looking to cope with the problem, rather than facing it head on.
The issue of processing large amounts of data is not necessarily new--most developers and IT staff can tell you about having too much information to deal with--but, the big difference is that there are new approaches, tools and technologies that can help alleviate the difficult in processing.

Over the course of the last 30 years or so the way that machines process transactions has changed, but so too has the vast amount of data that is being processed and collected, now with an eye toward real-time analysis of information.
This has led to the advent of a number of technologies that allow for data processing to be offloaded and managed in both structured and unstructured ways--examples include open-source projects like Memcached and Hadoop as well as NoSQL data storage mechanisms like Cassandra.
For the moment the blocking factor facing any and all of these technologies is the level of difficulty associated with using the software that wasn't initially designed to be used by less-skilled developers and IT staff.
Importantly, the rise of these big data products has introduced a new wave of vendors including Northscale (focused on Memcached and Membase), Cloudera (focused on Hadoop) and Riptano (focused on Cassandra) that have expertise in the technology and appear poised to ride the wave, assuming that enterprises are interested and willing to pay. (Disclosure: I am an advisor to Riptano.)
But there is no one specific technical approach that solves every problem, making it an interesting challenge for those attempting to implement these different products and also for the vendors trying to predict the future.
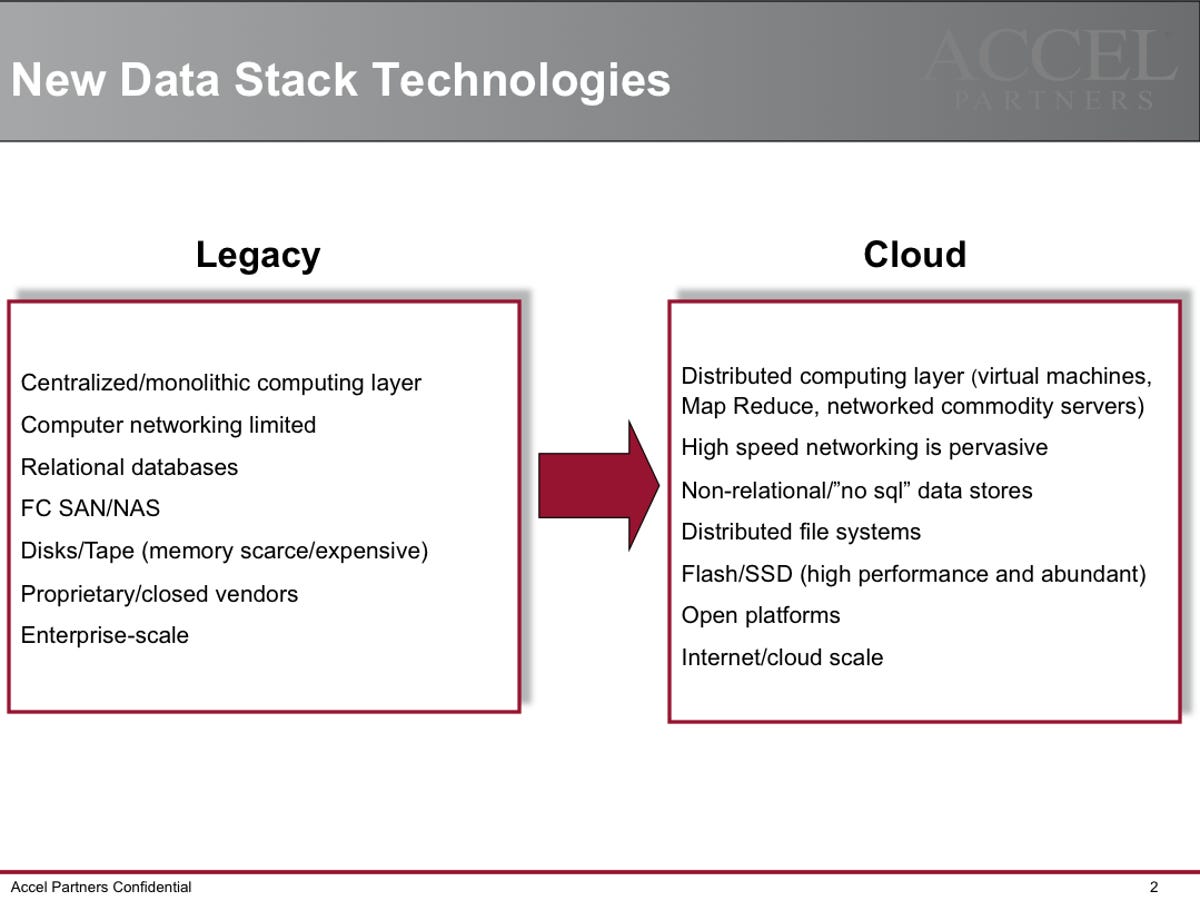
So while there are many ways to solve the problem the important thing is the approach. Monolithic legacy technologies are being replaced with distributed computational resources (often compute clouds) and relational databases can be replaced, or perhaps offset with NoSQL data stores that allow for extremely high volumes of transactions without requiring SQL-specific programmatic methods.
The question remains as to where these resources live, in a corporate data center or out on the Internet at providers like Amazon Web Services or Rackspace Cloud. Odds are a hybrid approach to processing and managing this data--both through internal compute clouds and public cloud offerings--is the path to success.
What remains to be seen is how quickly enterprises will make their way to the new world of big data, and how much consistency, in both application data and design matters across the variegated ways of customers currently manage their information.