Five ways to save a Web page
Internet Explorer, Firefox, and Google Chrome make it easy to save a Web page as an HTML file for viewing offline, but that is far from your only option when you want to preserve some or all of the content on a Web page.


The other day someone asked me how to save a copy of a Web page. The person wanted to preserve the content of the page--text and images--in a local file rather than simply bookmark the page's link to the hosting server.
There are many reasons why you would want to save the text and other content of a Web page. For example, you may want to access the information without a network connection. You may also want to record the page's content lest the information become unavailable for whatever reason. Pages go offline all the time, some never to return. Just ask anyone who has clicked a broken bookmark.
Here are five different ways to copy a Web page's content for offline browsing, plus a reason why you may never need to bookmark another page.
The Quick Draw McGraw approach: The fastest way to capture what's currently in the browser window is to press Alt+Print Screen in Windows to copy the currently active window, or Command+Shift+3 on a Mac to take a snapshot of the entire screen. (On a Mac, Command+Shift+4 lets you select the portion of the screen to capture.) Then open any image processor (such as Paint in Windows) and press Ctrl+V to paste the window or desktop capture into a new file. Save the file as a JPEG, PNG, BMP, or other image format.
The screen capture is fast, but you probably want to copy more of the page than can fit in one browser window, or you may want just some of the page's text or images, not the whole enchilada. Also, you won't be able to copy text from or otherwise interact with the duplicated content: it's one big image.
The Content Capture approach: To copy all of the page's content, press Ctrl+S to open the Save As dialog box. Internet Explorer, Mozilla Firefox, and Google Chrome let you save the page at the default "Web Page, complete" setting or "Web Page, HTML only." Firefox adds two other file-save options: "Text files" and "All files."
"Web Page, complete" saves the HTML file and a folder containing other elements on the page, such as images and scripts. When you open the local file in your browser, links, images, and other elements on the page may or may not work, depending on network connection, availability of the host Web server, and other variables.
The Firefox Help site explains your page-saving options in that browser. Microsoft's Help & How-to site provides the same information for IE 9.
The Text Only approach: If you merely want the page's text without images and interactive elements, the fastest way is to press Ctrl+A to select the entire page, press Ctrl+C to copy it, open any word processor or text editor, and click Edit > Paste Special > Unformatted text. The resulting text file includes all the text on the page, some of which you probably don't want, such as the page's site navigation.
The text-pasting is more precise if you use the mouse to select only the text you want to copy rather than the entire page. Then press Ctrl+C, open your text editor/word processor, and press Ctrl+V to paste the semi-formatted text. In many word processors, links in the resulting text will be Ctrl-clickable. Alternatively, you can click Edit > Paste Special > Unformatted text to paste plainly.
The Print as PDF approach: Google Chrome's built-in support for "printing" a page to a PDF file gives the browser an edge over Firefox and IE. Simply click the wrench in the top-right corner and choose Print > PDF > Save as PDF. In Windows the print-preview window lets you adjust the page layout from portrait to landscape, select only certain pages, and access other options by clicking Advanced.
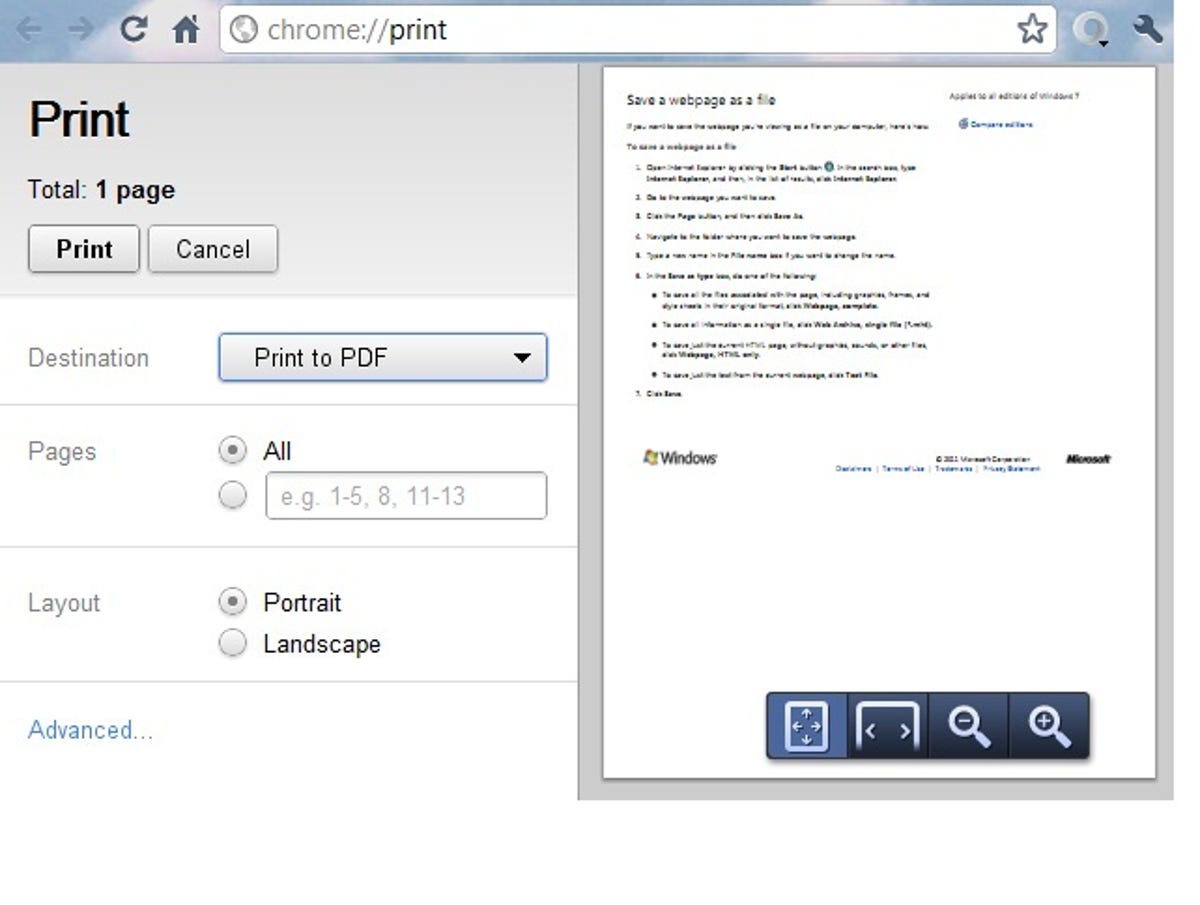
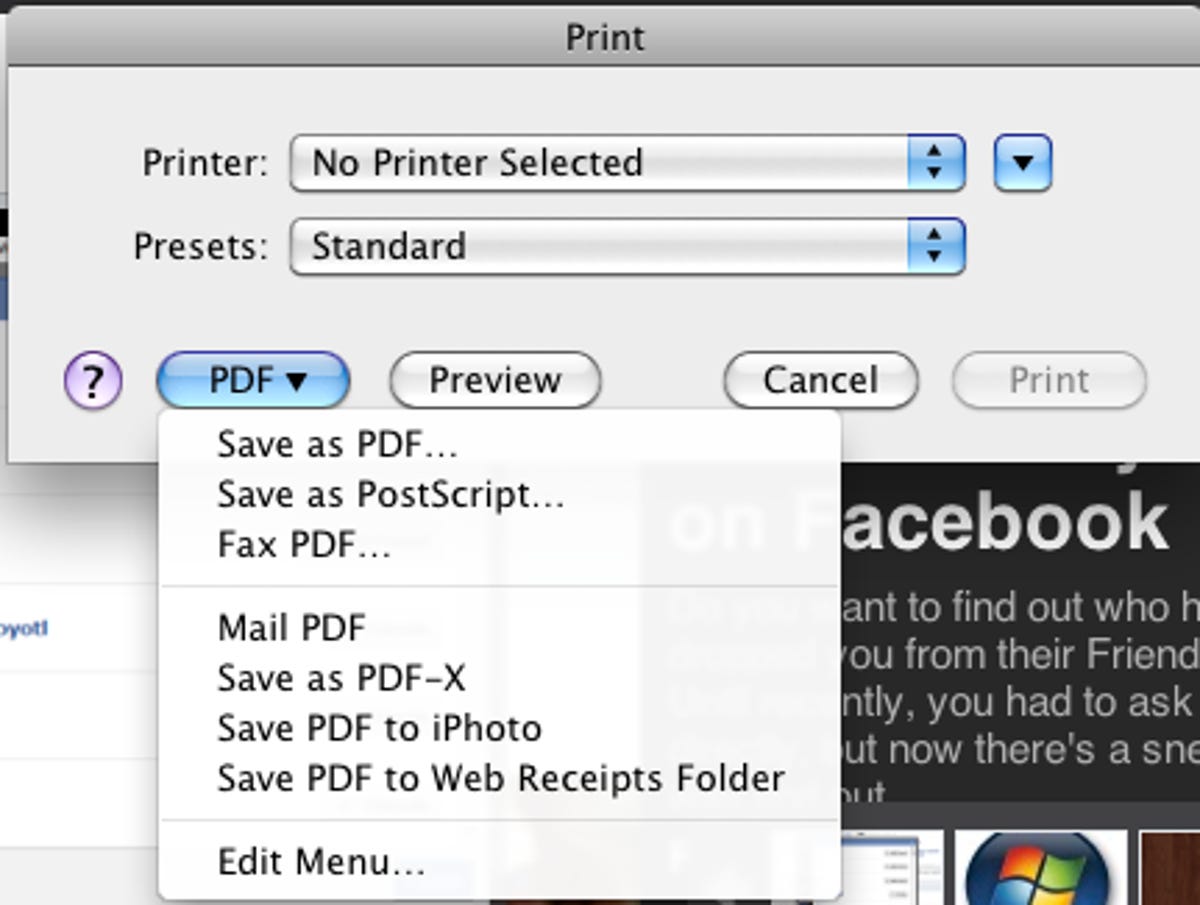
The Print dialog in the Macintosh versions of Chrome and Firefox (as well as every other Mac app) provides a PDF drop-down menu that lets you create a PDF of the page and fax or e-mail the PDF file, among other options. The Save As dialog lets you add a subject or keywords for the file. You can also require a password to open, copy, or print the PDF.
Firefox will list PDF options in the Print dialog on Windows PCs if the machine has PDF software installed. If you don't have a copy of Adobe Acrobat or another PDF program, Acro Software's free CutePDF Writer is an option. I first wrote about the program in a post from March 2008.
As the comments from that post indicate, there are dozens of other free-PDF options, but CutePDF Writer has stood the test of time, and now a version is available for 64-bit Windows 7.
Internet Explorer 9 lets you right-click a page and choose either "Convert to Adobe PDF" or "Append to existing PDF." You can also choose the XPS option in IE's Print dialog to create an XML Paper Specification version of the page. The Microsoft Developer Network site offers an XPS overview.
The Browser Plug-in approach: After you sign up for a free account with the Read It Later service, you can create a single list all the pages you've saved for offline viewing, regardless of which browser or PC you use. There's even versions of Read It Later for smart phones.
The Read It Later add-on for Firefox puts a button in the upper-right corner of the browser that provides quick access to your list of saved pages. You can filter, search, sort, or sync your list, and access your account options. Right-click anywhere on the page and choose Read This Page Later to add the current page to your offline-browsing list.
To add pages to your Read It Later list from Chrome and IE, drag the service's bookmarklets to the IE's Favorites toolbar and Chrome's bookmarks bar. If the bookmarks bar isn't visible in Chrome, click the wrench icon in the top-right corner, select Preferences, and check "Always show the bookmarks bar" under Basics.
The Google Web History alternative to bookmarks
A cottage industry has developed to help people manage their browser bookmarks and favorites, but it has been many months since I bookmarked a page. When I need to retrace my steps on the Web, I visit my Google Web History page, which lists everything I've searched for and every site I have visited in reverse-chronological order.
Many people prefer not to have their Web activities tracked so precisely. To prevent your history from being recorded, just sign out of your Google account. Better still, sign out and use an alternative to Google for your Web searches, such as the Ixquick metasearch engine I wrote about last May.
The fact is, I usually don't mind keeping a record of my online sessions, and on several occasions Google's history has come in handy. As I mentioned in the post I wrote about the service back in 2008, you can easily remove some or all of your history. Considering my Web history dates back almost five years, it serves as a personal time capsule. You know what they say about people who don't learn from the past.
Should anyone make the effort to crack into my Web history, about the only thing they would learn is how boring the life of a tech journalist truly can be.